
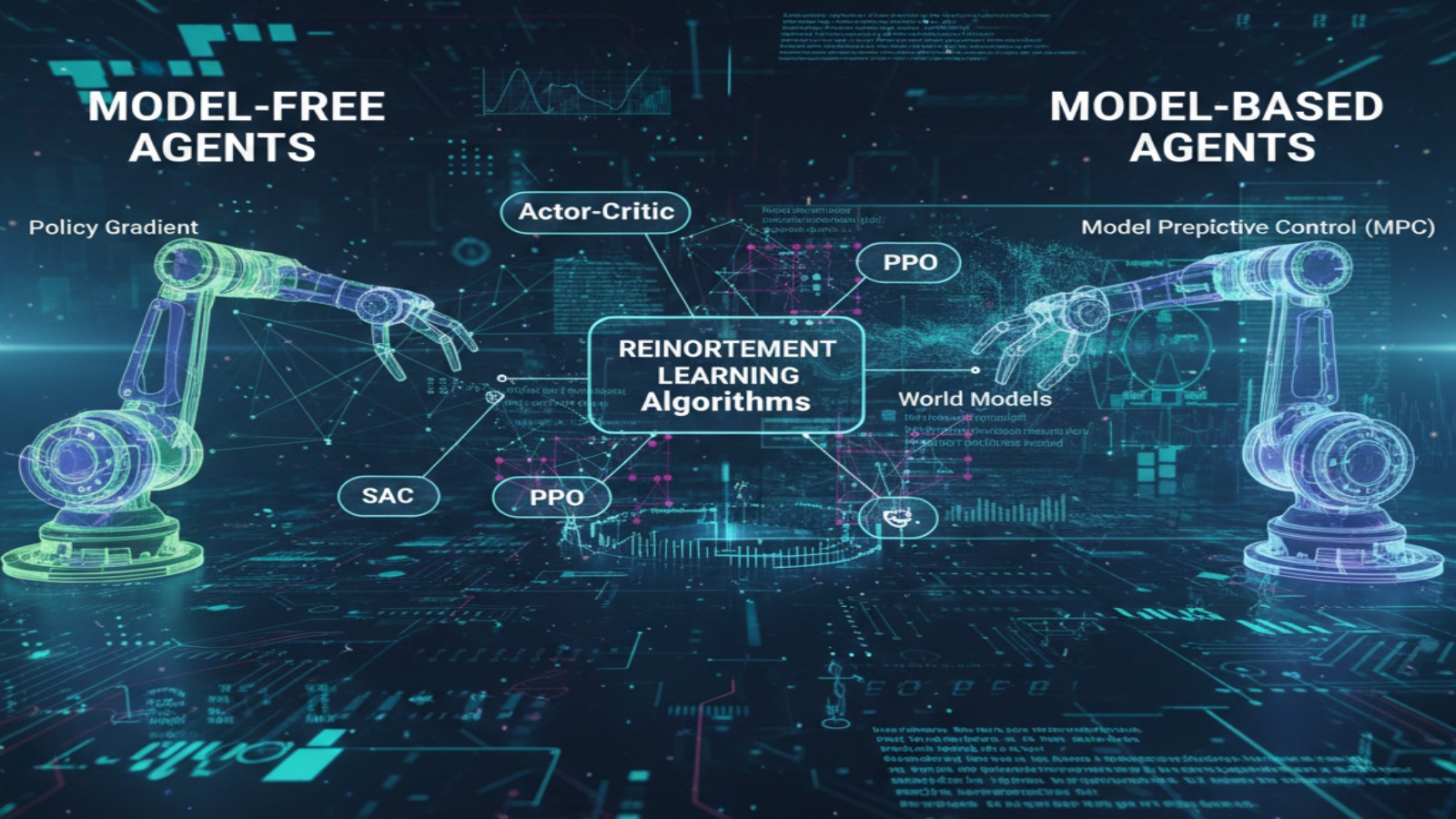


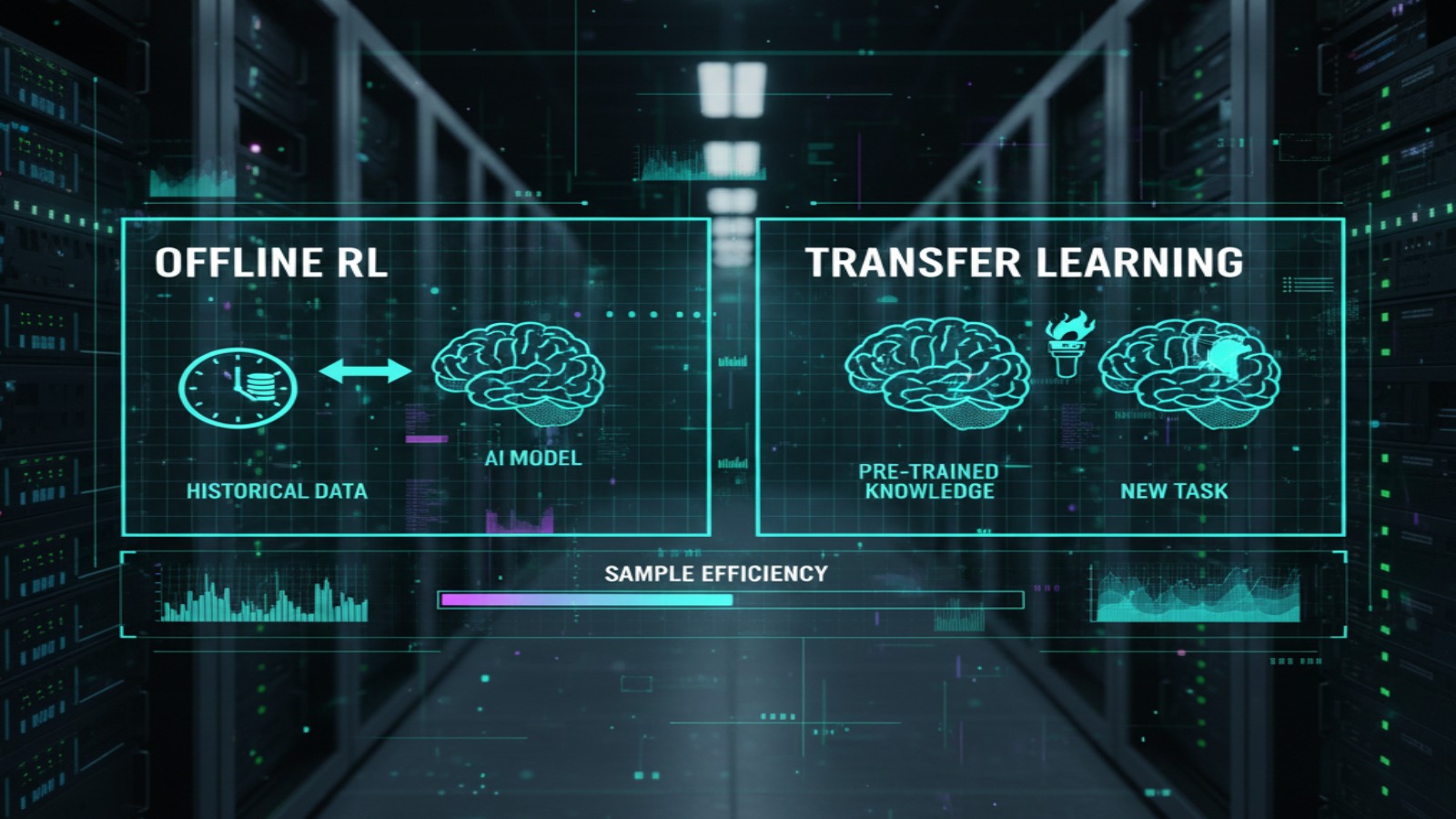
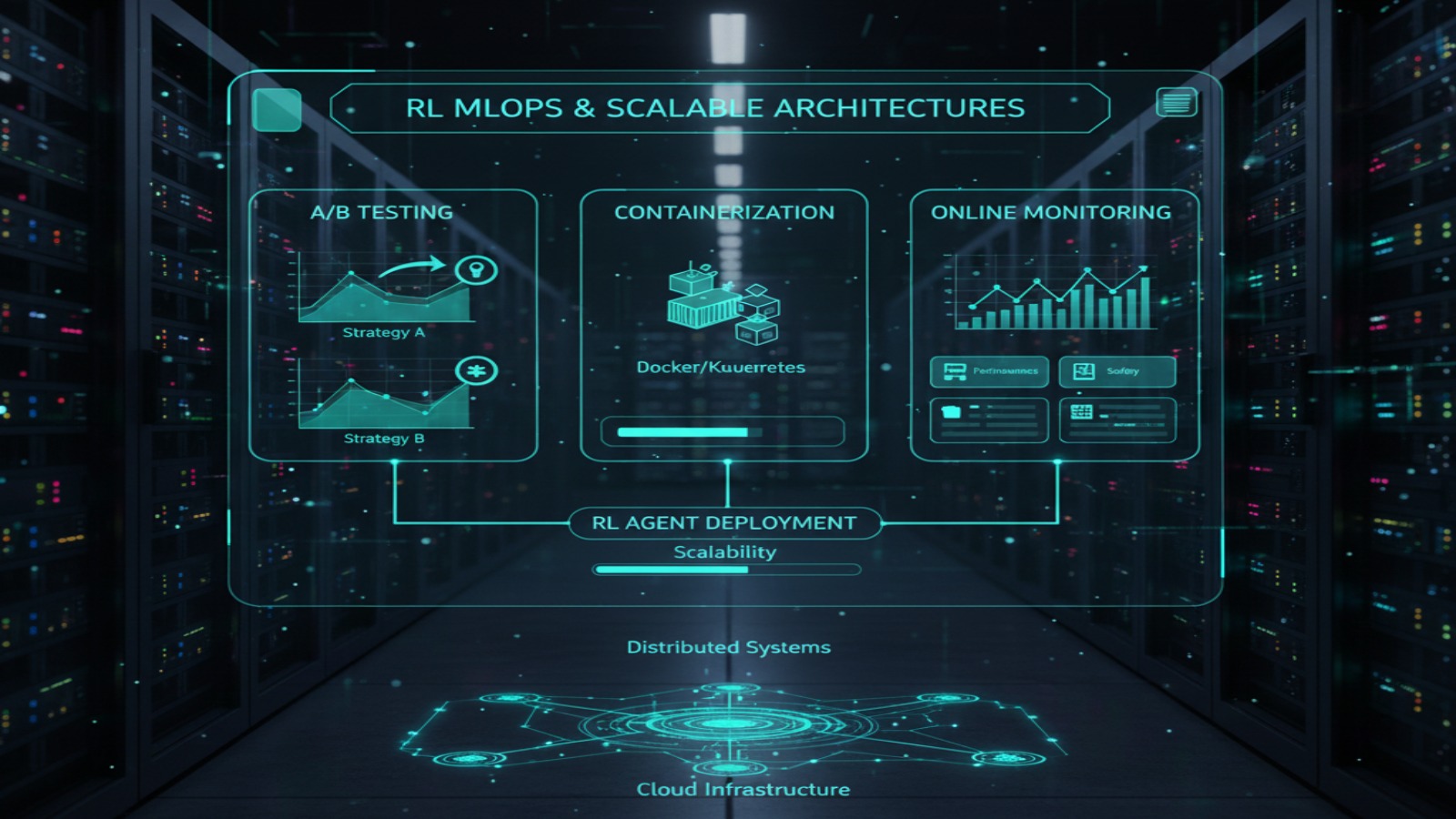





خروجی ها
عاملهای آموزشدیده و بستههای استنتاج (Docker / TorchScript / ONNX).
محیط شبیهسازی و سناریوهای تست همراه با اسکریپتهای ارزیابی.
مستندات فنی شامل معماری، تابع پاداش و نتایج آزمایش.
API برای کنترل و مانیتورینگ عامل، و داشبورد مانیتورینگ عملکرد.
برنامه پیادهسازی مرحلهای (PoC → Pilot → Production) و قرارداد SLA.